 Woka 기술 블로그
Woka 기술 블로그
Seq2Seq Decoder의 출력층: 은닉 상태로부터 실제 단어를 출력하기까지
이전 글에서 알아봤듯이, Seq2Seq 모델의 디코더에서는 각 시점마다 은닉 상태($h_t^d$)를 갱신하며, 이 상태를 기반으로 해당 시점의 최종 출력값($o_t$)을 결정합니다. 하지만 이 은닉 상태는 숫자로 표현된 내부 벡터일 뿐, 우리가 원하는 구체적인 단어(“la”, “musique” 등)는 아닙니다. 따라서 디코더에는 이 은닉 상태를 바탕으로 어떤 단어를 출력할지 결정하는 출력층(output layer)이 포함됩니다. 출력층의 내부 동작은 세 단계로 구성됩니다.
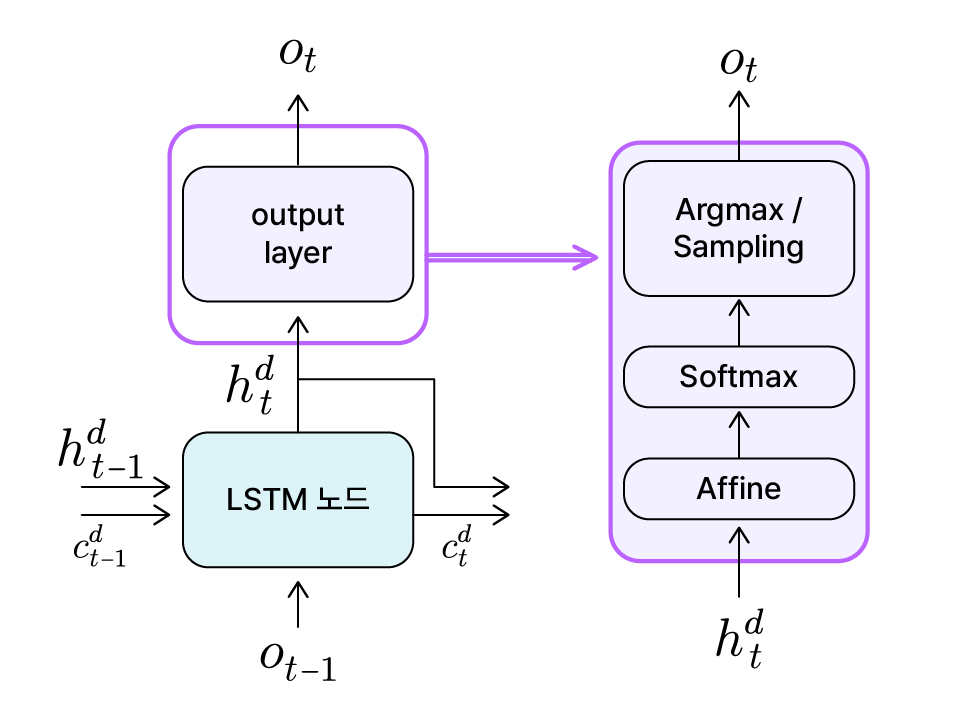
Decoder 출력층 개요
STEP 1. Affine 연산: 점수(score) 계산하기
먼저, 디코더의 은닉 상태($h_t^d$)에 선형 변환을 적용합니다. 앞선 글들에서 여러번 설명했듯이 가중치(weights, $W$)를 곱하고 편향(bias, $b$)을 더하는 과정입니다. 이러한 선형 변환을 Affine 연산 (Affine Transformation)이라고 합니다.
$$ z_t = W h_t^d + b $$
$z_t$는 모델이 학습한 가중치 $W$와 편향 $b$를 통해 계산된 벡터입니다. 이 벡터의 각 원소는 어휘 사전(모델이 출력할 수 있는 모든 단어의 집합) 속 각각의 단어가 출력될 가능성을 수치적으로 표현하고 있습니다. 모델은 점수가 높을수록 해당 단어가 출력될 가능성이 높다고 판단합니다.
“She loves music”을 “Elle aime la musique”로 번역해낸 모델의 디코더에서 $t=3$ 시점에 일어나는 과정을 예로 들어보겠습니다.
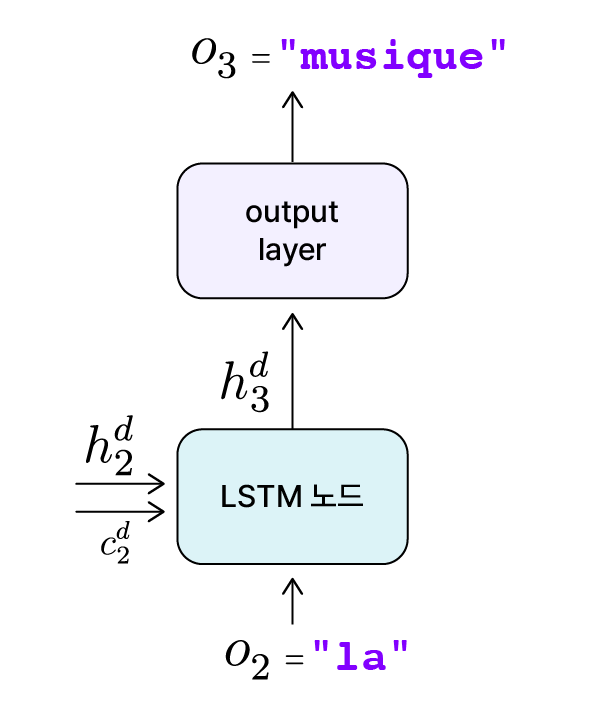
영-프 번역모델 Decoder t=3 시점
$t=3$에서의 상황은 다음과 같습니다.
- 모델 전체의 입력 시퀀스와 예상 출력 시퀀스: “She loves music” → “Elle aime la musique”
- 직전 노드의 출력 $o_2$ =
"la" - 직전 은닉 상태($h_2^d$)와 셀 상태($c_2^d$)에 반영된 정보
- “She loves music”을 인코딩한 컨텍스트 벡터
- 디코더에서 이전 시점($t=0, 1, 2$)에 출력한 순차적인 단어
"Elle","aime","la"
- 현재 디코더는
"la"를 입력받아 다음 단어"musique"를 출력해야 합니다.
이 디코더의 어휘 사전이 ["elle", "il", "aime", "la", "musique", "chien"]라고 가정하겠습니다. $t=3$에서 갱신된 은닉 상태 $h_3^d$가 출력층에 전달되면 먼저 Affine 연산을 거치게 됩니다. 그 결과로 생성된 $z_3$은 어휘 사전의 각 단어에 대응되는 점수를 담은 벡터입니다.
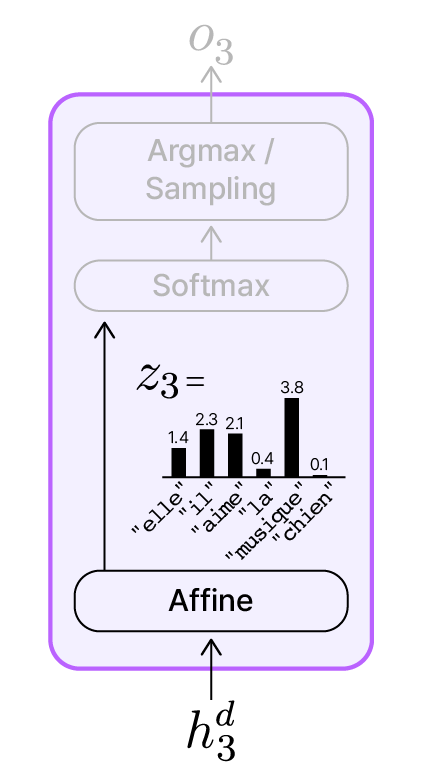
Affine 연산의 점수 벡터
$z_3$의 각 원소가 어떤 단어의 점수를 표현하는지 확인해보면, “musique”에 해당하는 점수(3.8)가 가장 높다는 것을 알 수 있습니다. 하지만 이 숫자들은 아직 확률이 아니며, 상대적인 “선호도”에 가깝습니다.
STEP 2. Softmax 함수: 점수를 확률로 변환
Affine 연산으로 얻은 점수 벡터 $z_t$는 아직 단순한 상대적 수치일 뿐입니다. 이제 이를 각 단어가 다음으로 등장할 확률처럼 해석해야 합니다. 이 때 사용되는 활성화 함수가 임의의 실수 벡터를 확률분포로 바꾸는 Softmax 함수입니다.
$$ y_t = \texttt{softmax}(z_i)= \frac{e^{z_{i}}}{\sum_{j=1}^K e^{z_{j}}} \ \ \ for\ i=1,2,\dots,K $$
Softmax 함수는 모든 점수를 0과 1 사이의 값으로 변환하고, 전체 확률의 합은 항상 1이 되도록 만듭니다. Softmax 함수의 결과인 벡터 $y_t$는 어휘 사전 내 각 단어가 $t$ 시점에서 출력될 확률을 나타내는 벡터가 됩니다.
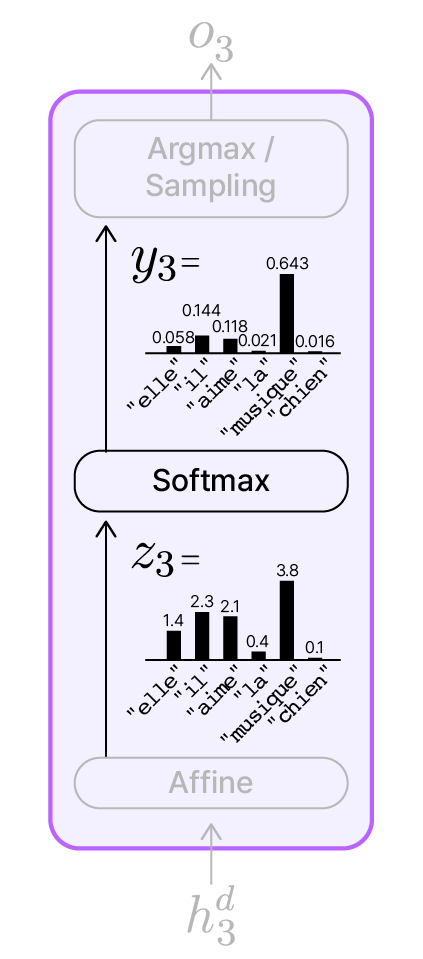
Softmax 함수의 확률분포 벡터
영-프 번역 Seq2Seq 모델에서 $t=3$ 시점의 출력층에서 일어나는 일을 이어서 살펴보겠습니다. Affine 연산을 통해 점수 벡터 $z_3$가 계산 되었고, 이를 softmax함수에 통과시켜 전체 확률의 합이 1인 확률분포 벡터 $y_3$을 계산(소수점 셋째자리 반올림)했습니다. 각 단어의 확률을 보면 "musique"가 가장 높은 확률 0.643을 가지게 되었습니다.
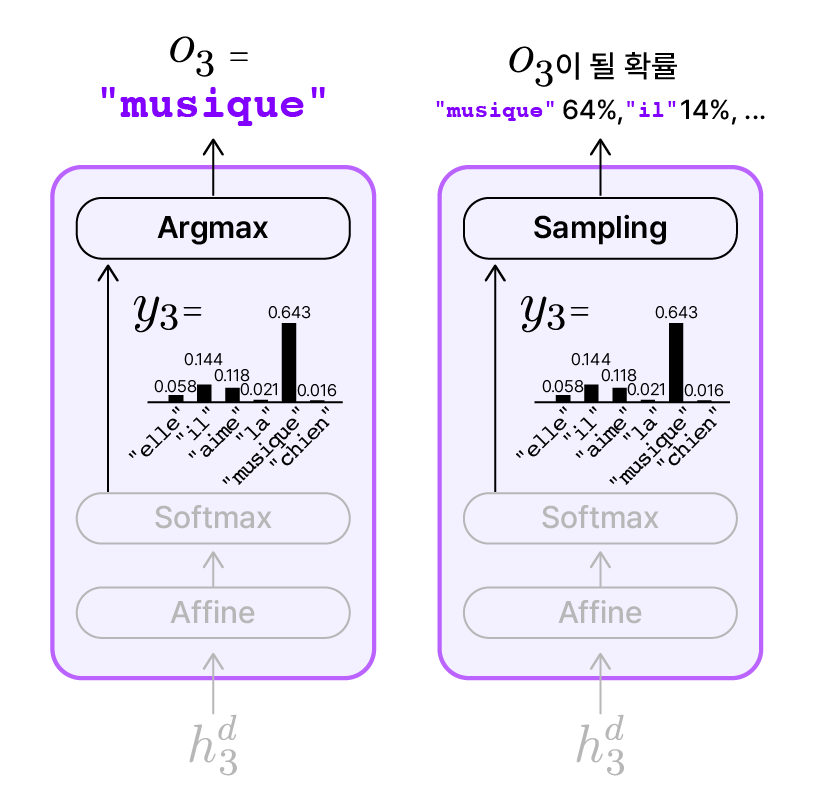
STEP 3. 단어 선택: 안정적인 argmax 혹은 다양한 sampling
확률 분포($y_t$)가 계산되었으면, 이제 실제로 어떤 단어를 출력할지 선택해야 합니다. 여기에는 보통 $y_t$에서 확률이 가장 높은 단어를 선택하는 Argmax 방식이나 확률 분포 자체를 따라 단어를 확률적으로 선택하는 Sampling 방식을 사용합니다.
Argmax와 Sampling
☝️ Argmax 방식
- 가장 직관적인 방법입니다.
- 어휘 전체에 대한 확률 분포 $y_t$에서 가장 확률이 높은 단어 선택합니다.
- 같은 입력에 대해 같은 출력을 냅니다. 따라서 ‘결정적’인 방식입니다.
- 번역이나 챗봇처럼 정확하고 일관된 응답이 필요한 상황에 적합합니다.
- 영-프 번역 Seq2Seq의 디코더에서 $y_3$을 전달받으면 항상
"musique"를 출력합니다.
🎲 Sampling 방식
- 확률 분포 $y_t$를 기반으로 무작위로 단어를 선택합니다.
- Temperature Sampling, Top-k Sampling 등 여러 종류가 있습니다.
- 다양한 표현 생성이 필요한 상황(예: 대화, 글쓰기 등)에 사용됩니다.
- 영-프 번역 Seq2Seq의 디코더에서 $y_3$을 전달받으면 출력이 매번 다를 수 있습니다: 높은 확률(약 64%)로
"musique"가 선택될 가능성이 가장 높고, 예외적으로 확률이 낮은"il"(약 14%)나"aime"(약 12%)가 선택될 수도 있습니다.
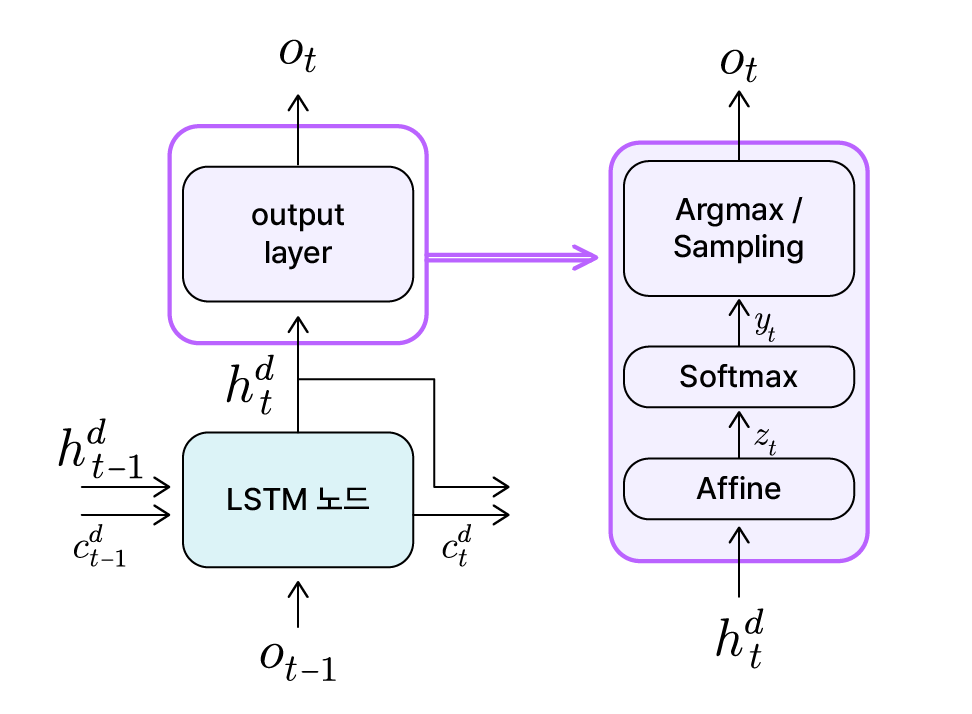
Decoder 출력층 정리
Decoder 출력층
- Affine 연산: 현 시점에서 갱신된 은닉 상태 $h_t^d$ → 각 단어의 점수 벡터 $z_t$
- Softmax: 점수 벡터 $z_t$ → 각 단어의 확률 분포 $y_t$
- Argmax 혹은 Sampling: 확률 분포 $y_t$ → 방식에 따라 최종 출력 단어 $o_t$ 선택
Seq2Seq 모델은 이러한 과정을 Decoder의 매 시점 반복하면서, 전체 문장을 생성해 나갑니다.