 Woka 기술 블로그
Woka 기술 블로그
Seq2Seq: 인코더와 디코더로 이루어진 시퀀스 변환의 기본 구조
Seq2Seq(Sequence-to-Sequence)는 입출력 언어가 다른 언어 번역이나, 주어진 질문에 대해 응답을 생성하는 대화 모델처럼 입력 시퀀스와 출력 시퀀스의 길이가 다른 경우를 처리할 수 있는 모델입니다. 이번 글에서는, RNN 기반의 모델을 응용한 Seq2Seq가 어떤 구조로, 어떤 원리로 동작하는지 알아보겠습니다.
딥러닝에서 가장 기본적인 구조인 ANN(Artificial Neural Network, 관련 글)은 고정된 길이의 입력만 받을 수 있습니다. 하지만 현실의 데이터는 길이가 일정하지 않은 경우가 많습니다. 이를 처리하기위해 순환 신경망(RNN, 관련 글)과 RNN 기반의 모델인 LSTM(관련 글)과 GRU(관련 글)가 등장했습니다.
시퀀스 데이터를 처리하는 RNN은 입력 데이터의 길이를 고정하지 않고 순차적으로 정보를 학습할 수 있습니다. 예를 들어 문장을 입력받아 문장 속 단어의 품사를 출력하는 RNN 모델에 “They love music”을 입력합니다.
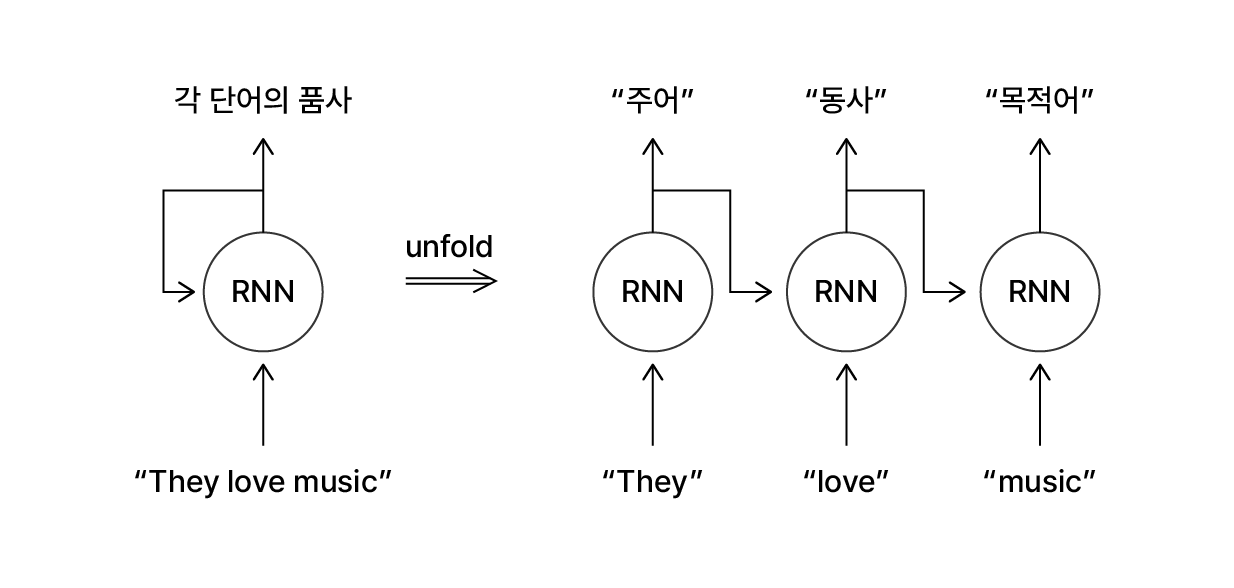
문장 속 단어의 품사를 구별하는 RNN 예시
모델은 문장을 구성하는 3개의 단어를 순차적으로 입력 받으며, 이전에 입력된 단어들을 참고해 각 단어의 품사를 출력해냅니다. ‘love’라는 단어 이전에 ‘They’를 입력 받아 정보를 학습했기 때문에, 모델은 ‘love’가 명사가 아닌 동사로 사용됨을 알 수 있습니다. 결과적으로 이 모델은 “주어, 동사, 목적어”라는 3개의 출력을 만들어냅니다. 입력 시퀀스의 단어 개수에 대응하는 개수의 출력을 만든 셈이죠.
이렇게 RNN은 각 입력 데이터의 길이에 따른 각 시점마다 출력을 내놓기 때문에 입력 데이터와 출력 데이터의 길이가 동일한 경우에 적합합니다. 하지만 3개의 영어 단어로 이루어진 문장 “She loves music”을 4개의 프랑스어 단어로 이루어진 같은 뜻의 문장 “Elle aime la musique”로 번역하는 것처럼, 입력 시퀀스와 출력 시퀀스의 길이가 다른 경우에는 어떻게 해야할까요?
LSTM 기반의 Encoder와 Decoder를 합친 Seq2Seq
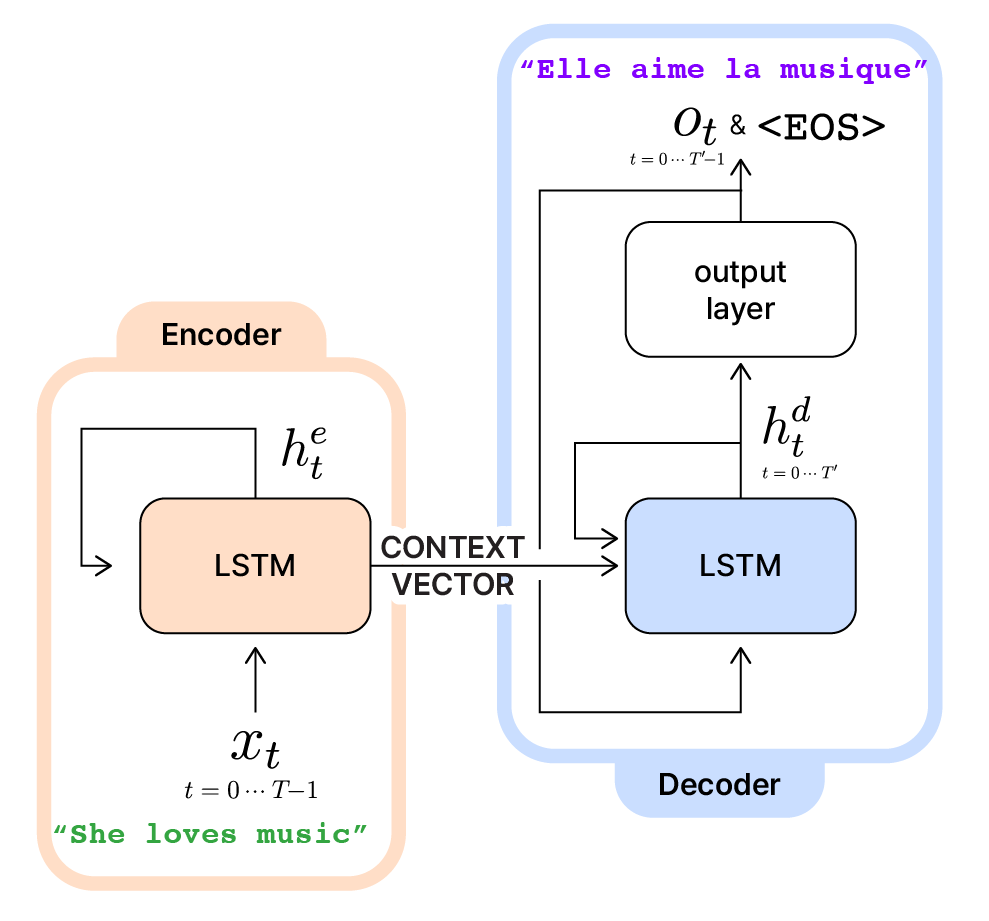
Seq2Seq의 구조 개요
Seq2Seq는 그림처럼 서로 다른 LSTM을 포함하는 Encoder(인코더)와 Decoder(디코더)를 조합해 만든 모델입니다. Seq2Seq에서 인코더와 디코더의 역할은 다음과 같습니다.
Encoder(인코더)
- 인코더의 은닉 상태($h_t^e$)와 셀 상태($c_t^e$)는 $e$를 위첨자로 사용해 encoder(인코더)에서 처리되는 데이터임을 표시하겠습니다.
- $T$ 길이의 입력 시퀀스($x_t (t=0 \cdots T-1)$)를 입력받아 LSTM을 $T$번 순환하며 인코더의 은닉 상태인 $h_t^e (t=0 \cdots T-1)$를 업데이트 합니다.
- 최종 은닉 상태($h_{T-1}^e$)는 입력 시퀀스를 압축한 정보인 context vector라고 불리며, 디코더로 전달됩니다.
Decoder(디코더)
- 디코더의 은닉 상태($h_t^d$)와 셀 상태($c_t^d$)는 $d$를 위첨자로 사용해 decoder(디코더)에서 처리되는 데이터임을 표시하겠습니다.
- 인코더로부터 입력 시퀀스에 대한 압축 정보인 context vector를 전달받아 초기 은닉 상태로 사용합니다. 이후 각 시점에서 은닉 상태($h_t^d$)와 셀 상태($c_t^d$)를 갱신합니다.
- 갱신된 은닉 상태를 바탕으로 각 시점에서는 출력 시퀀스인 $o$와 문장의 끝을 알리는 토큰
"<EOS>"를 출력해냅니다.- 출력 시퀀스의 길이가 $T’$일 때, 디코더는 LSTM을 $T’$번 순환하며 출력 시퀀스($o$)를 구성하는 값을 출력합니다. 그리고 마지막으로 LSTM을 한번 더 순환하여 토큰
"<EOS>"를 출력합니다. - 인코더의 $T$와 디코더의 $T’$은 같을 수도, 다를 수도 있습니다.
- 출력 시퀀스의 길이가 $T’$일 때, 디코더는 LSTM을 $T’$번 순환하며 출력 시퀀스($o$)를 구성하는 값을 출력합니다. 그리고 마지막으로 LSTM을 한번 더 순환하여 토큰
- 디코더의 LSTM은 첫 번째 시점($t=0$)과 이후 시점($t=1 \cdots T’$)에서 입력되는 값이 다릅니다.
- $t=0$:
"<SOS>"토큰을 입력값으로 사용 - $t=1 \cdots T’$: 직전 노드의 출력($o_{t-1}$)을 입력값으로 사용
- $t=0$:
셀과 노드라는 명칭을 정의하자!
Seq2Seq에서는 두 개의 LSTM이 사용되기 때문에, 이 글에서 모델의 구조를 지칭하는 명칭을 정리하겠습니다.
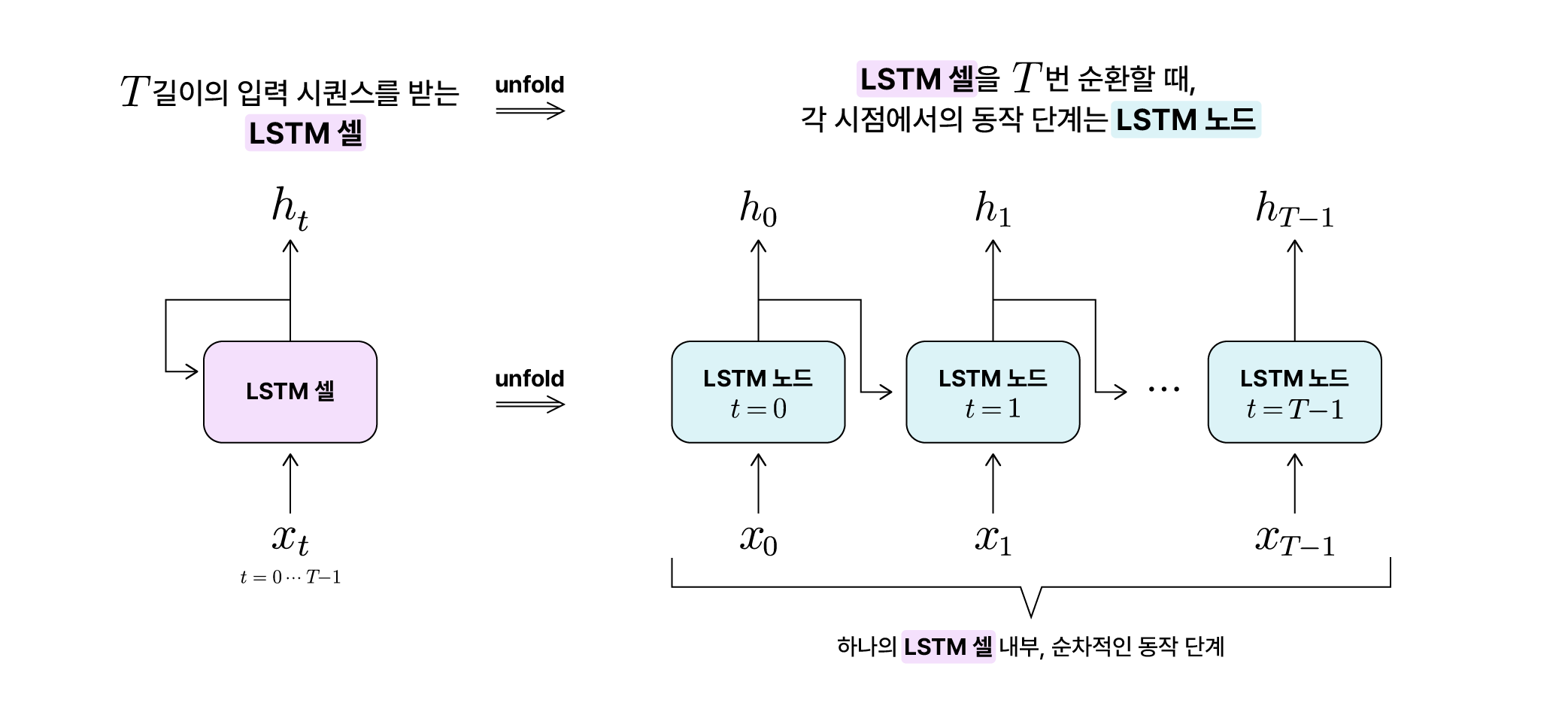
셀과 노드 명칭 정리
하나의 LSTM 모델을 LSTM 셀이라고 하겠습니다. 이 LSTM 셀에 $T$ 길이의 입력 시퀀스($x_t (t=0 \cdots T-1)$)가 전달되면, 총 $T$번에 걸쳐서 입력 시퀀스가 순차적으로 전달됩니다. 이때 각 시점에서의 LSTM 셀 내부 동작 단계를 $t$시점에서의 LSTM 노드라고 하겠습니다. 다시 말해 하나의 LSTM 셀을 unfold하면 순서대로 연결된 $T$개의 LSTM 노드가 펼쳐지는 것입니다.
Seq2Seq에는 인코더와 디코더가 각각 다른 LSTM을 쓴다고 했으니, Seq2Seq는 2개의 LSTM 셀로 구성되어있다고 할 수 있습니다. 그리고 Seq2Seq가 처리하는 시퀀스 데이터는 입력 시퀀스의 길이와 출력 시퀀스의 길이가 다를 수 있으니 인코더 LSTM 셀의 노드 수와 디코더 LSTM 셀의 노드 수는 서로 다를 수 있습니다.
그럼 이제, Seq2Seq를 구성하는 두 LSTM 셀 중 첫 번째 셀인 인코더에 대해 살펴보겠습니다.
Encoder: 입력 시퀀스를 요약해 컨텍스트 벡터로
‘암호화하는 것’을 뜻하는 인코더(Encoder)의 핵심 역할은, 입력 시퀀스의 정보를 하나의 벡터로 잘 표현하는 것입니다. 여기서 잘 표현한다는 것은, LSTM이 $T$개의 조각으로 나누어진 입력 시퀀스를 순차적으로 처리하면서 중요한 정보는 강조하고 덜 중요한 정보는 덜 강조하며 이를 은닉 상태에 반영해 ‘기억’을 업데이트한다는 뜻입니다.
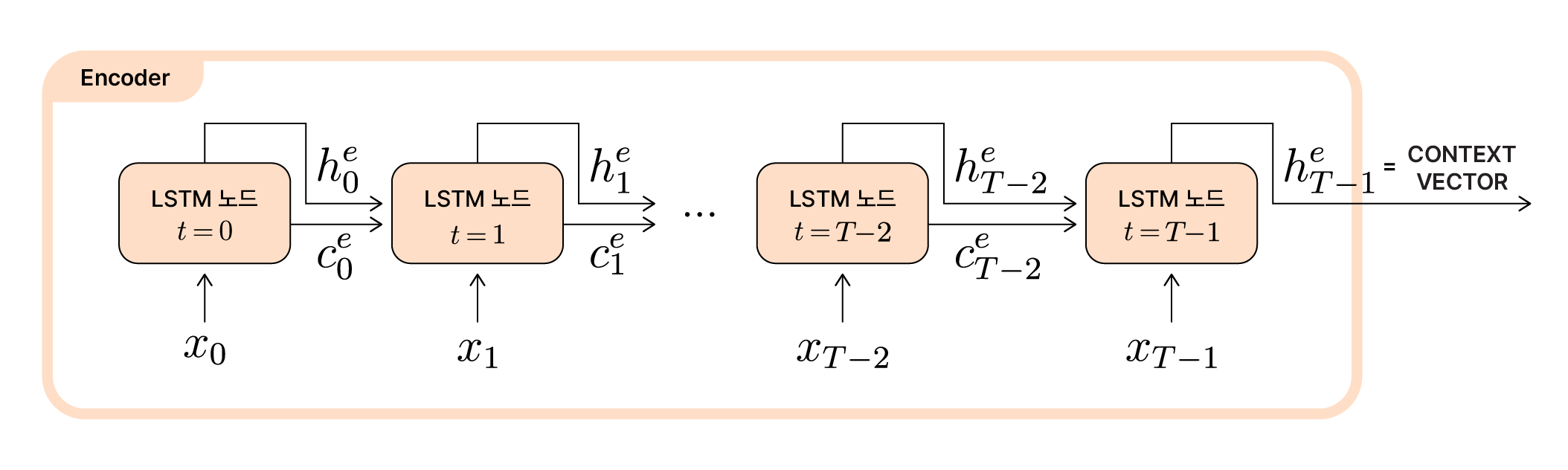
Encoder LSTM 셀의 unfold 구조
위 그림을 보면 우리가 이전 글에서 알아봤던 기본적인 LSTM 셀의 동작과 동일하다는 것을 알 수 있습니다. 만약 영어를 프랑스어로 번역하는 Seq2Seq모델에 “She loves music”을 입력한다면 아래 그림과 같겠죠?
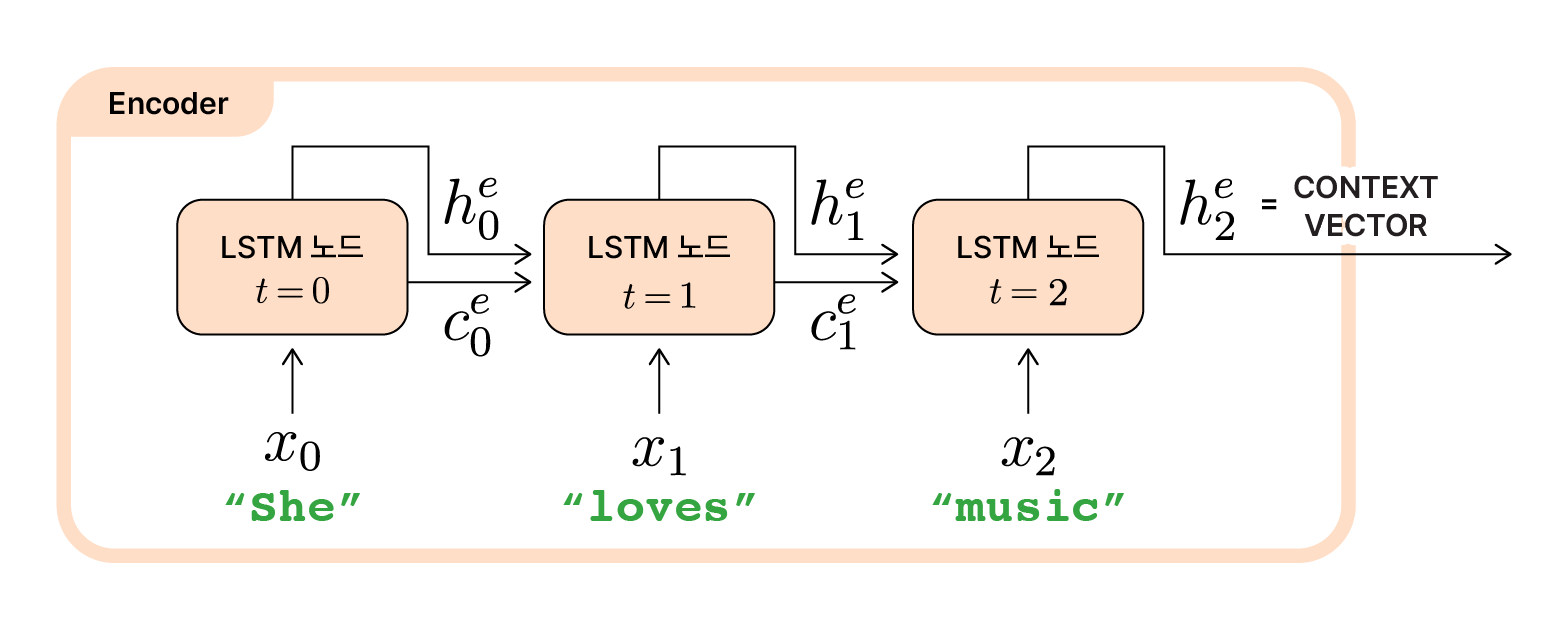
“She loves music”을 입력받은 Encoder LSTM 셀의 unfold 구조
각 노드에서는 해당 시점($t$)에 입력된 데이터($x_t$)와 직전 노드에서 전달받은 셀 상태($c_{t-1}^e$) 그리고 은닉 상태($h_{t-1}^e$)를 바탕으로 셀 상태와 은닉 상태를 갱신($c_t^e$, $h_t^e$)합니다. 그렇게 시점 $t=0$부터 시점 $t=T-1$까지 입력 시퀀스의 길이에 맞게 LSTM 셀을 순환합니다.
입력 시퀀스의 마지막 입력값($x_{T-1}$)을 처리하고 나면, 마지막 은닉 상태인 ($h_{T-1}^e$)이 계산됩니다. 인코더의 이 마지막 시점에서 처리된 최종 은닉 상태가 바로 입력 시퀀스 전반의 정보를 압축해 담고있는 하나의 벡터, context vector(컨텍스트 벡터)입니다. 인코더에서 생성되는 컨텍스트 벡터는 이후 디코더로 전달되기 때문에, 고정된 차원을 갖게 됩니다.
잠깐, context vector로 인코더의 최종 셀 상태($c_{T-1}^e$)가 아닌 최종 은닉 상태($h_{T-1}^e$)를 쓰는 이유?
컨텍스트 벡터는 디코더에 전달되어 출력 시퀀스를 생성하는 데에 사용됩니다. 따라서 LSTM의 내부에서 기억을 유지하는 셀 상태($c_{T-1}^e$)보다 출력 생성에 직접적으로 연관된 은닉 상태($h_{T-1}^e$)가 더 적합합니다.
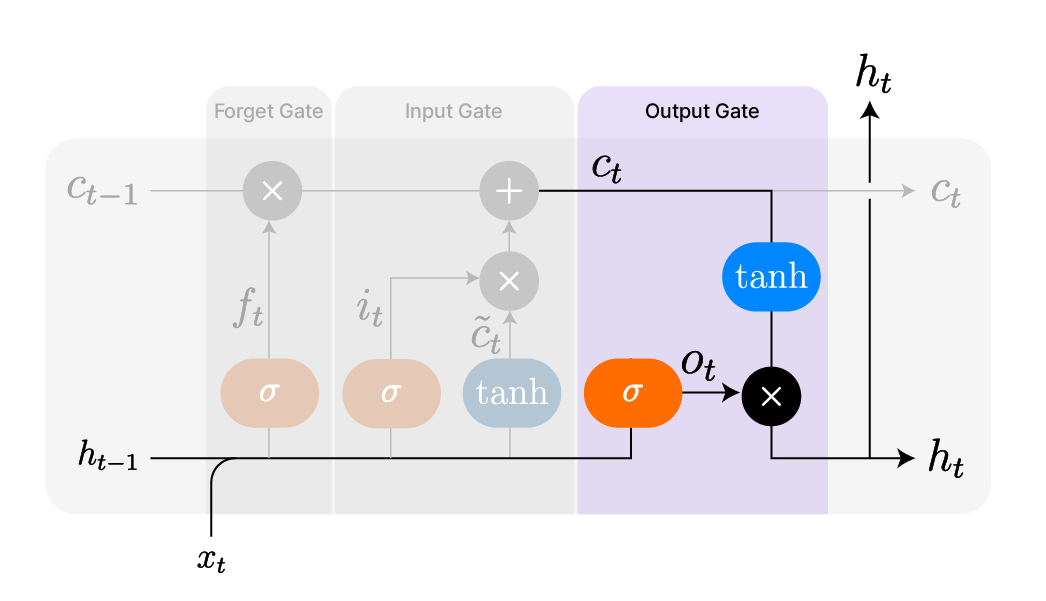
LSTM의 출력 게이트에서 갱신되는 은닉 상태
LSTM의 구조와 동작원리를 알아볼 때, 셀 상태($c_t$)는 LSTM의 장기 기억 역할을 담당한다고 했습니다. 따라서 LSTM을 반복 순환하면서 입력 시퀀스 전체에 걸쳐 누적된 정보를 보관합니다. 그와 달리 LSTM의 은닉 상태($h_t$)는 현재 시점에서 출력으로 사용될 정보를 포함하는 단기 기억의 역할을 담당합니다.
인코더에서 계산된 컨텍스트 벡터는 디코더에 넘겨져 입력 시퀀스의 정보를 전달합니다. 디코더는 이 컨텍스트 벡터를 활용해 바로 출력 시퀀스를 계산하기 때문에, 컨텍스트 벡터로 출력에 바로 사용할 정보를 필요로 합니다. 인코더의 최종 셀 상태($c_{T-1}^e$)는 장기적으로 기억을 저장하는 데에 적합하지만, 직접 출력에 사용하기에는 가공이 덜 된 상태입니다. 반면 인코더의 최종 은닉 상태($h_{T-1}^e$)는 마지막 시점까지 누적된 셀 상태($c_{T-1}^e$)를 출력 게이트에 통과시켜 정제한 데이터입니다. 기억보다는 ‘지금 뭘 출력해야 하지?’라는 정보가 필요한 디코더에게는 인코더의 최종 은닉 상태($h_{T-1}^e$)가 더 유용한 것이죠.
실제로 Seq2Seq를 구현할 때, ‘디코더에 전달할 컨텍스트 벡터로 무엇을 쓰느냐’는 선택사항에 해당하기도 합니다. 딥러닝 프레임워크인 TensorFlow 등에서 Seq2Seq를 구현하면 인코더의 최종 셀 상태($c_{T-1}^e$)와 최종 은닉 상태($h_{T-1}^e$) 모두를 디코더에 전달합니다.
하지만 일반적으로 논문 등에서 언급하는 컨텍스트 벡터는 주로 은닉 상태로 정의됩니다. 이유는 앞서 말했듯, LSTM의 내부에서 기억을 유지하는 셀 상태보다 출력 생성에 직접적으로 연관된 은닉 상태가 더 적합하기 때문입니다.
Decoder: 압축된 컨텍스트 벡터에서 새로운 출력을
Encoder와 반대로 ‘해독하는 것’을 뜻하는 디코더(Decoder)는 인코더에서 넘겨받은 컨텍스트 벡터를 기반으로 출력 시퀀스를 생성합니다. 영어를 프랑스어로 번역하는 Seq2Seq 모델은 “She loves music”이 압축되어 표현된 컨텍스트 벡터를 전달받아, 같은 뜻의 프랑스어 표현인 “Elle aime la musique”를 출력하는 것이죠.
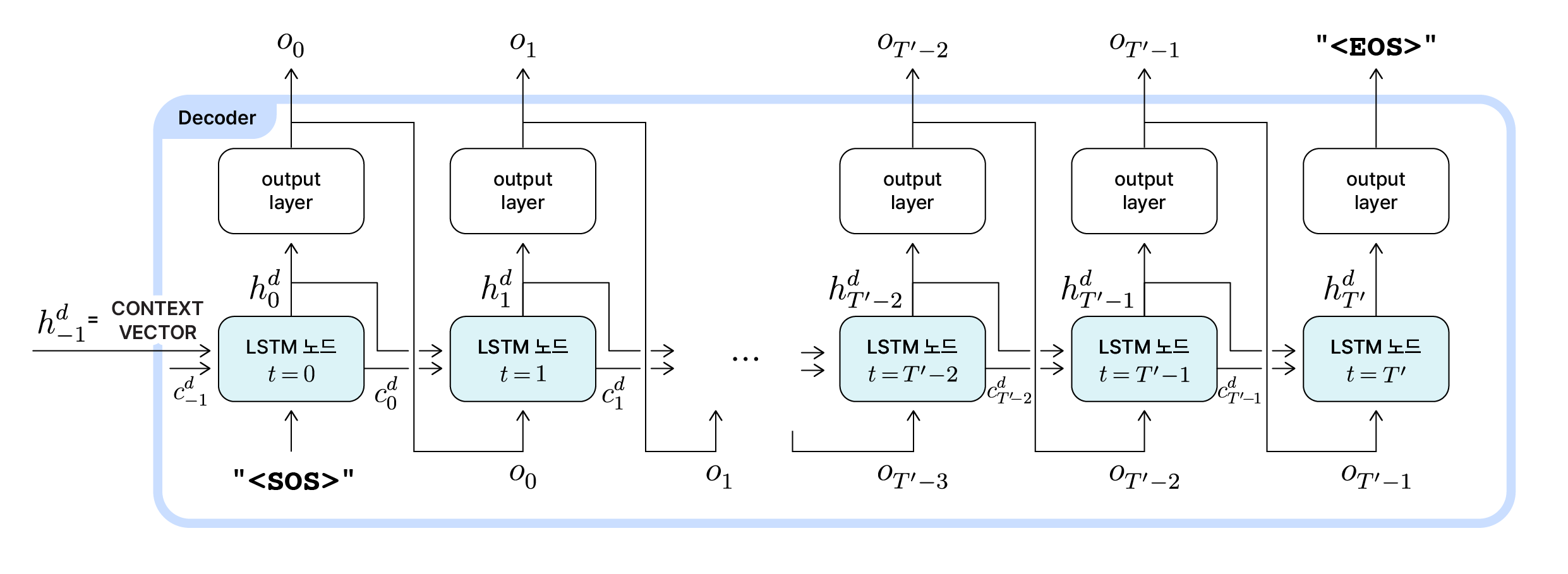
Decoder의 동작 개요
디코더의 LSTM 노드에서 계산된 은닉 상태($h_t^d$)는 출력층(output layer)으로 전달되고 각 시점의 노드에서 출력될 결과($o_t$)가 생성됩니다. 따라서 기본적인 LSTM으로만 구성되었던 인코더와 달리 각 시점마다 output layer를 포함하고 있습니다. 디코더의 내부 동작을 하나씩 살펴보겠습니다.
Decoder LSTM의 $t=0$
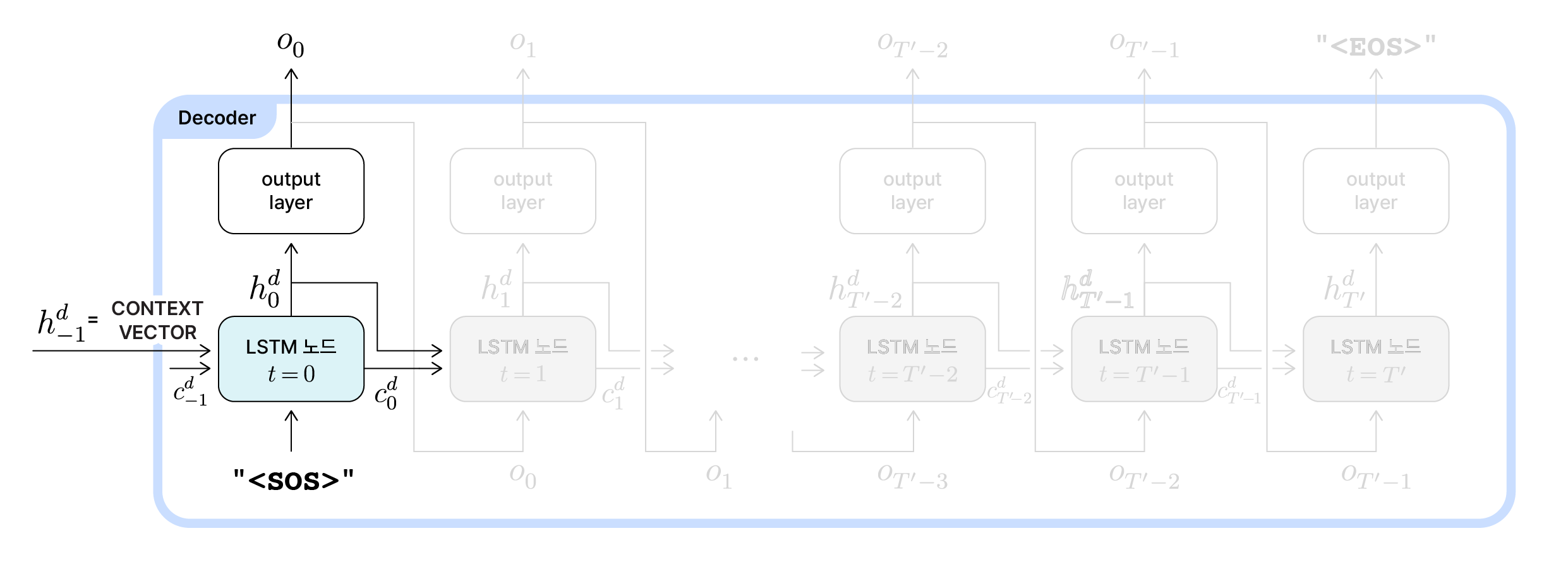
Decoder 초기 동작
디코더에서 첫 번째 시점인 $t=0$에서는 입력 시퀀스 전체를 요약한 컨텍스트 벡터가 초기 은닉 상태($h_{-1}^d$)로 전달됩니다. 초기 셀 상태($c_{-1}^d$)는 일반적으로 0 벡터로 초기화되거나 인코더의 최종 셀 상태($c_{T-1}^e$)를 전달받습니다. 이 시점에서의 입력값은 문장의 시작(Start of Sentence)을 뜻하는 토큰 "<SOS>"입니다.
- 초기 입력:
"<SOS>" - 초기 은닉 상태: $h_{-1}^d$ = $h_{T-1}^e$ (인코더의 최종 은닉 상태) = $\texttt{context vector}$
- 초기 셀 상태: $c_{-1}^e$ = $\vec{0}$ (0벡터) 혹은 $c_{-1}^d$ = $c_{T-1}^e$ (인코더의 최종 셀 상태)
$t=0$시점의 LSTM 노드는 이 세 정보를 바탕으로 은닉 상태와 셀 상태를 갱신해 $h_0^d$와 $c_0^d$를 계산하고 다음 노드로 두 값을 전달합니다.
그리고 현재 노드에서의 출력 시퀀스를 생성하기 위해 은닉 상태 $h_0^d$를 출력층(output layer)에 통과시킵니다. 은닉 상태($h_0^d$)는 출력층을 통해 확률 분포로 변환된 뒤, 이 시점에서 최종적으로 출력될 값 $o_0$이 선택됩니다. 출력층에서는 affine 연산, softmax 함수, argmax방식, sampling 방식 등 단어의 확률 분포를 구하고 최종 출력 값을 선택하는 과정이 일어납니다. 이 부분은 이어지는 글에서 설명하고 있으니, 더 알아보고 싶으신 분은 이어지는 글을 참고해주세요!
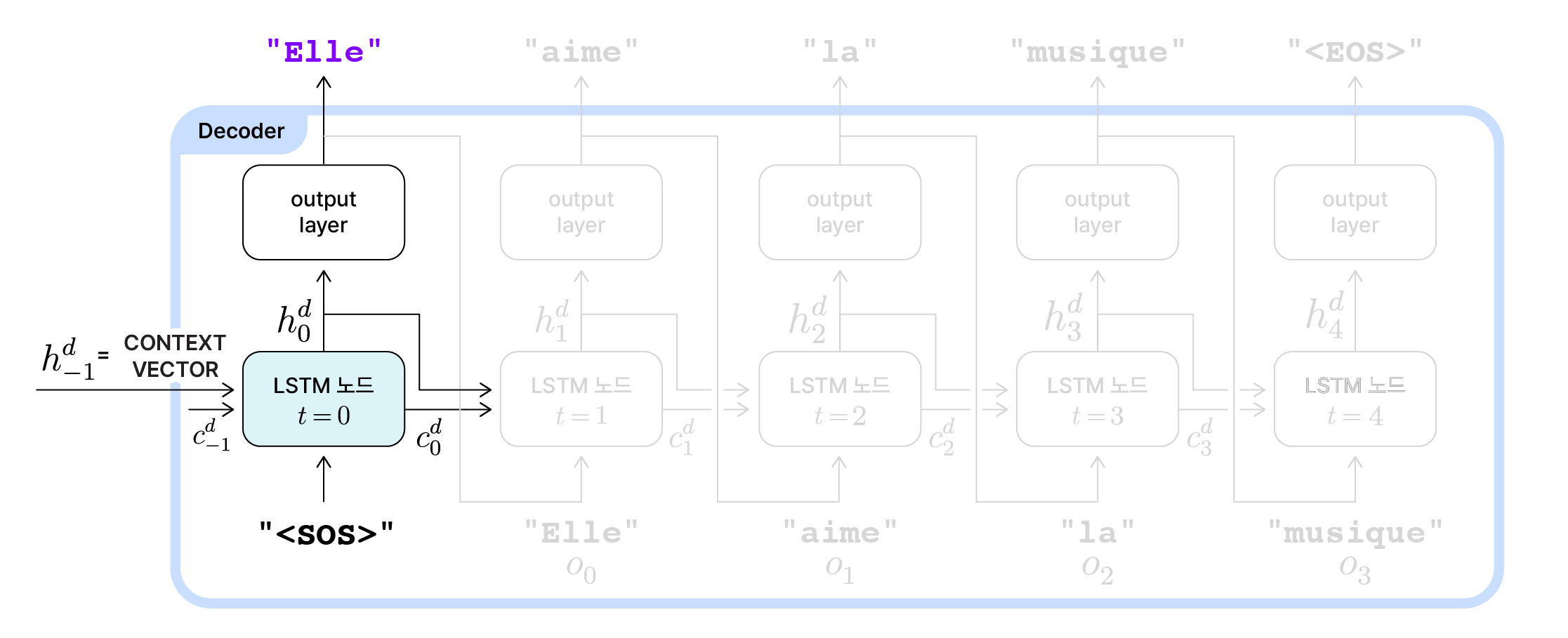
Decoder 초기 동작 예시
앞서 사용한 영어-프랑스어 번역 Seq2Seq 모델 예시를 그대로 적용해보겠습니다. 인코더에서 넘겨받은 컨텍스트 벡터($h_{T-1}^e$)에는 입력 시퀀스인 “She loves music”를 압축한 정보가 들어있습니다. 이 컨텍스트 벡터는 디코더의 초기 은닉 상태($h_{-1}^d$)로 사용됩니다. 그 다음, 프랑스어 문장을 생성해야하는 디코더의 초기 입력값으로 "<SOS>"가 사용됩니다. 이를 바탕으로 $t=0$ 시점에서 갱신된 은닉 상태($h_0^d$)가 계산됩니다. 출력층에서는 이 은닉 상태를 반영해 “je”, “tu”, “elle” 등 수많은 프랑스어 단어들이 이 문장에서 처음으로 등장할 수 있는 확률을 계산합니다. 그리고 최종적으로 첫 출력값($o_0$)으로 “Elle”을 선택합니다.
이렇게 출력 시퀀스의 첫 번째 출력값이 결정되었습니다.
Decoder LSTM의 나머지 시점
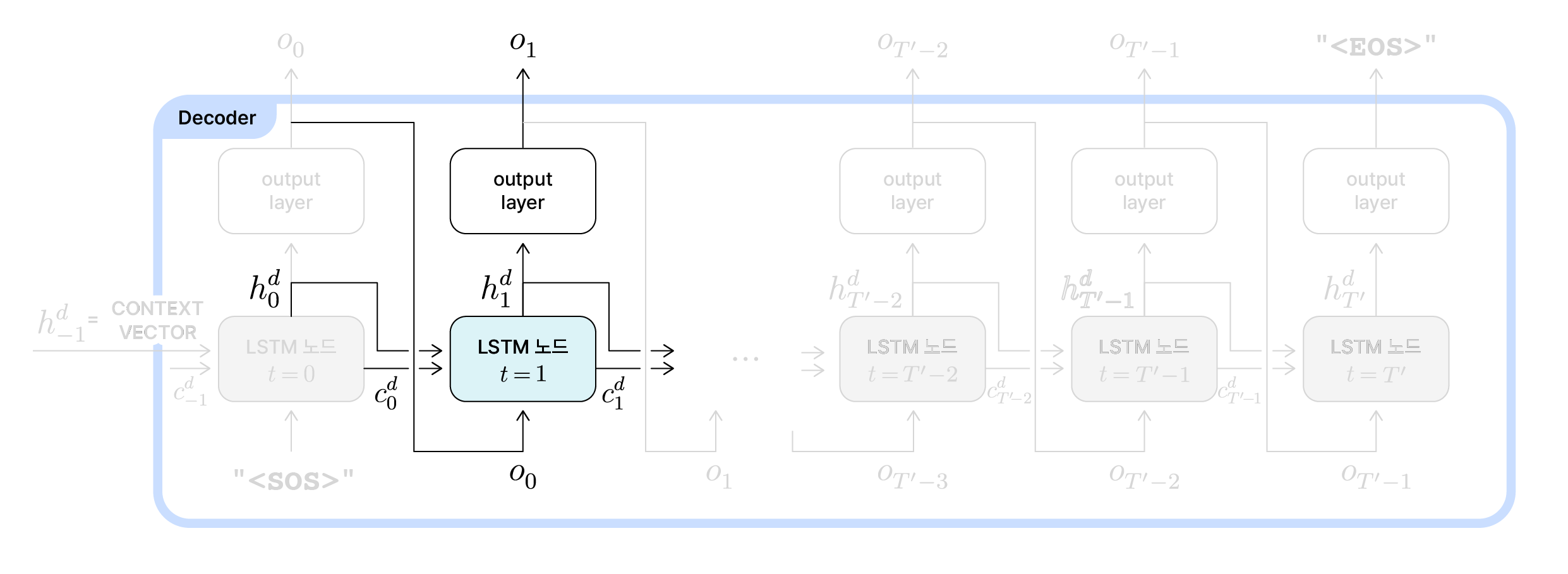
Decoder의 t=1 동작
이후 시점들($t=1 \cdots T’$)에서의 기본적인 동작은 일반적인 LSTM 모델과 동일합니다. 직전 노드의 은닉 상태($h_{t-1}^d$)와 직전 노드의 셀 상태($c_{t-1}^d$)를 전달받아 각각 갱신합니다.
한 가지 주의를 기울여야하는 것은 LSTM 노드에 사용되는 입력값들입니다. 그림을 보면 알 수 있듯이, 두번째 노드($t=1$시점의 노드)부터는 직전 노드의 출력값($o_{t-1}$)이 해당 노드의 입력값으로 전달됩니다. $t=1$시점의 두번째 노드에서는 $o_0$이 입력값으로 전달되고 있습니다.
세 정보(직전노드 은닉 상태와 셀 상태, 입력값)가 전달되고 그 이후의 과정은 디코더 LSTM의 $t=0$시점의 동작과 동일합니다. 현 시점에서의 은닉 상태($h_1^d$)와 셀 상태($c_1^d$)를 갱신해 이후 노드에 전달합니다. 또 갱신된 은닉 상태는 출력층에 전달되어 $t=1$ 시점에서의 출력값인 $o_1$를 결정하게 됩니다.
이 과정을 영-프 번역 모델에 적용하면 아래의 그림과 같습니다.
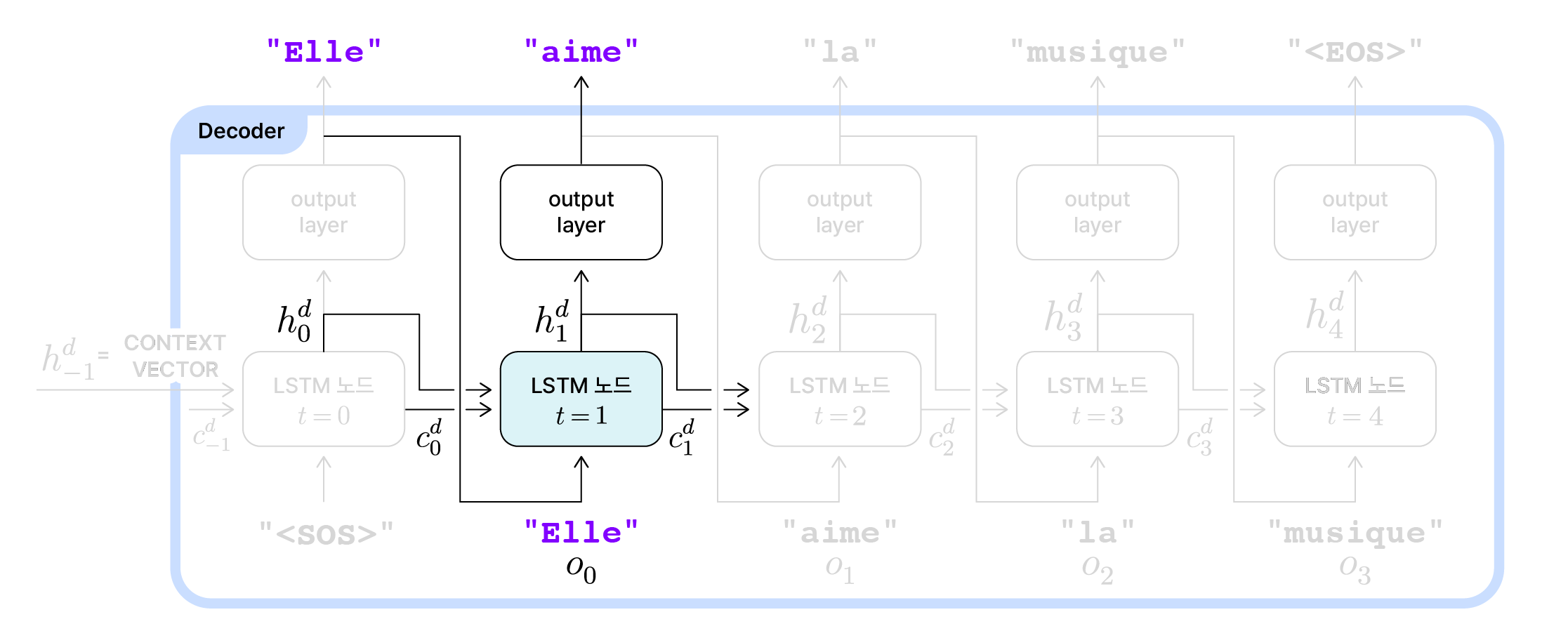
Decoder의 t=1 동작 예시
$t=1$시점의 LSTM노드는 직전 은닉 상태($h_0^d$)와 셀 상태($c_0^d$)를 전달받습니다. 그리고 직전 노드의 출력값($o_0$)인 “Elle”을 입력값으로 사용하고 있습니다. 이제 이 세 정보를 바탕으로 은닉 상태와 셀 상태를 갱신하고, 갱신된 은닉 상태를 사용해 $t=1$ 시점의 출력값($o_1$)을 “aime”으로 결정합니다.
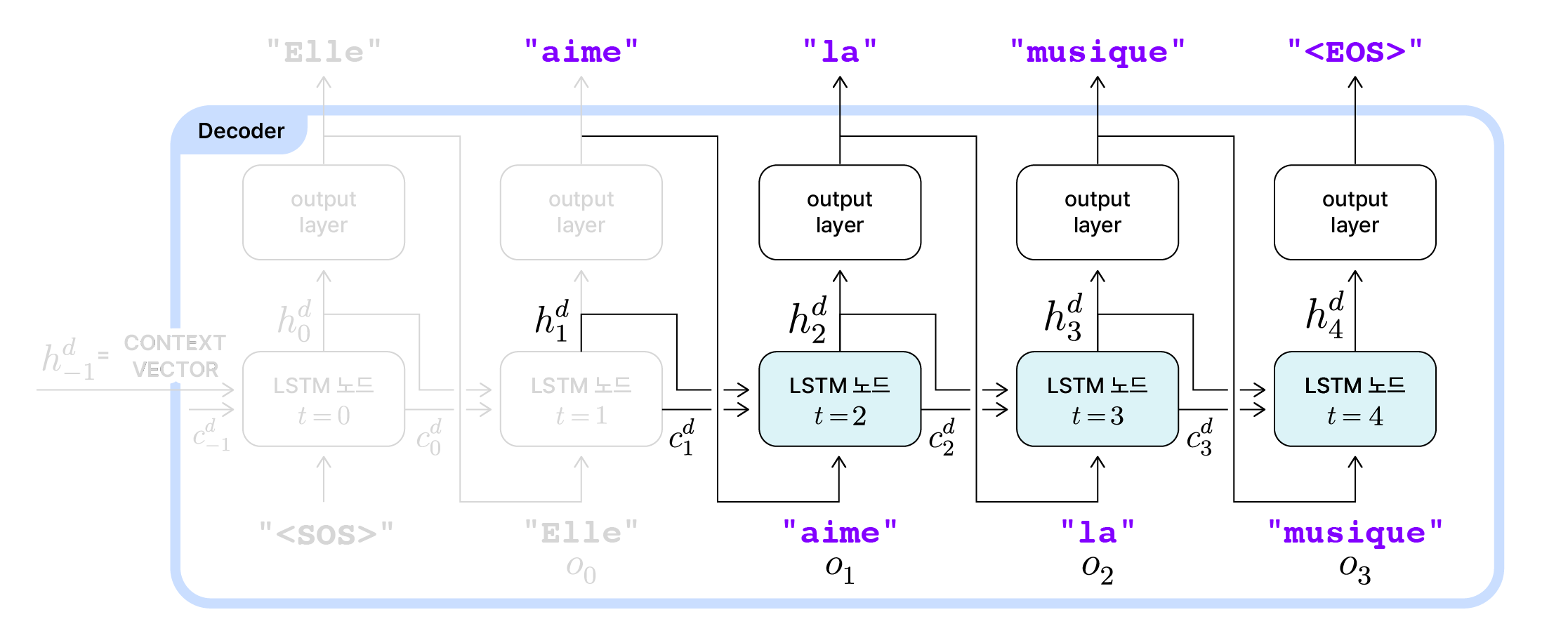
Decoder의 나머지 시점 동작 예시
이후 시점에서도 동일한 과정이 반복됩니다. 직전 노드의 출력값($o_{t-1}$)을 전달받아 은닉 상태($h_t^d$)와 셀 상태($c_t^d$)를 갱신한 뒤, 갱신된 은닉 상태를 바탕으로 다음 출력값($o_t$)을 결정합니다.
그렇게 $t=3$시점까지 진행이 되면, 여기까지 출력된 시퀀스는 “Elle aime la musique”입니다. 영어 문장 “She loves music”과 단어 수는 다르지만 뜻은 정확히 일치하는 문장입니다. 출력 시퀀스의 길이($T’$)는 4고, LSTM 노드도 $t=0, 1, 2, 3$으로 총 4번 순환 했습니다. 여기서 문장을 끝내면 되는데, 그 판단은 LSTM 노드를 한번 더 순환하며 내려집니다.
$t=4$시점의 노드는 “Elle aime la”가 반영된 직전 노드의 은닉 상태 $h_3^d$와 셀 상태 $c_3^d$를 전달 받습니다. 그리고 직전 노드의 출력값($o_3$)인 “musique”를 입력값으로 사용합니다. 이 세 정보를 합쳐보면 ‘이 시점에서는 더이상 출력을 이어갈 필요가 없다’는 정보를 계산해낼 수 있고, 그 정보는 디코더의 최종 은닉 상태인 $h_4^d$에 반영됩니다. 이 정보를 전달받은 출력층에서는 ‘이 시점에서 문장을 끝내겠다’는 선택을 하고 그 표시로 문장의 끝(End of Sentence)을 뜻하는 토큰 "<EOS>"를 출력합니다.
따라서 출력 시퀀스의 길이($T’$)가 4임에도 불구하고, 디코더에서는 "<EOS>"까지 포함해 총 5번, 즉 $T’+1$번 LSTM 노드를 반복합니다.
Seq2Seq의 한계
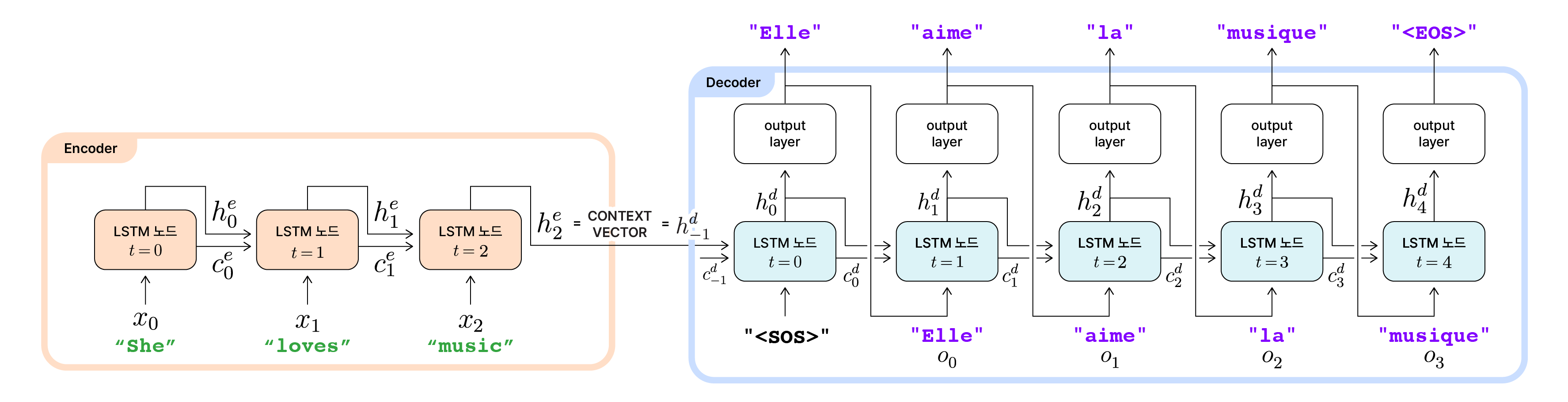
Encoder와 Decoder 예시
영어 문장 “She loves music”을 입력 시퀀스로 입력받아 같은 의미의 프랑스어 문장 “Elle aime la musique”를 출력 시퀀스로 생성하는 Seq2Seq의 전체 과정을 그린 그림입니다.
인코더와 디코더가 서로 다른 LSTM 셀을 사용하기 때문에, 입력 시퀀스의 길이(이 경우 $T=3$)와 상관없이 모델의 목적을 잘 달성한 출력 시퀀스(이 경우 길이는 $T’=4$)가 생성될 수 있었습니다.
하지만 Seq2Seq에도 한 가지 중요한 한계가 있습니다. 입력 시퀀스의 길이와 상관 없이, 디코더는 오직 인코더의 최종 은닉 상태($h_{T-1}^e$) 하나만을 통해 전체 입력 정보를 전달받습니다. 이 때 컨텍스트 벡터의 차원은 고정되어 있어, 아주 긴 입력 시퀀스의 정보를 압축해 담기에는 한계가 있습니다. 결과적으로 디코더가 출력 시퀀스를 생성할 때 중요한 정보를 놓칠 수도 있습니다. 입력 시퀀스의 길이가 길어질수록 정보 손실이 발생할 위험이 커진다면, 대량의 텍스트를 생성해야하는 번역의 품질이나 긴 문장 생성의 정확도에도 한계가 생깁니다.
이러한 문제를 해결하기 위해 등장한 것이 바로 Attention 매커니즘입니다. 다음 글에서는 이 Attenton이 어떻게 Seq2Seq의 한계를 극복하고, 더욱 정밀한 시퀀스 변환을 가능하게 했는지 살펴보겠습니다.